
CrossGeoNet: A Framework for Building Footprint Generation of Label-Scarce Geographical Regions
Installation
You can get the code from GitHub
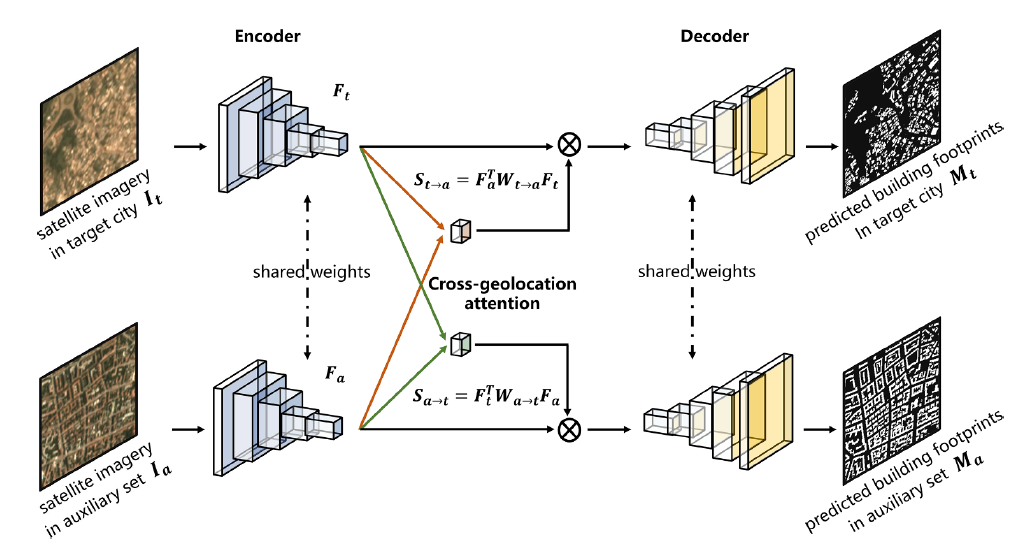
We propose to learn cross-geolocation attention maps in a co-segmentation network, which is able to improve the discriminability of buildings within the target city and provide a more general building representation in different cities. In this way, the limited supervisory information resulting from insufficient training examples in target cities can be compensated. Our method is termed as CrossGeoNet, and consists of three elemental modules: a Siamese encoder, a cross-geolocation attention module, and a Siamese decoder. More specifically, the encoder learns feature maps from a pair of images from two different geo-locations. The cross-location attention module aims at learning similarity based on these two feature maps and can provide a global overview of common objects (e.g., buildings) in different cities. The decoder predicts segmentation masks of buildings using the learned cross-location attention maps and the original convolved images.
Citations
Li, Qingyu, Lichao Mou, Yuansheng Hua, Yilei Shi, and Xiao Xiang Zhu. “CrossGeoNet: A Framework for Building Footprint Generation of Label-Scarce Geographical Regions.” International Journal of Applied Earth Observation and Geoinformation 111 (2022): 102824.